はじめまして。Cシステム開発グループの伊藤です。
アットホームには2021年に新卒で入社し、主に「不動産情報サイト アットホーム」の基盤周りの新規開発と運用保守を担当しています。
私はプログラミングはもちろん、IT系の知識は全くない未経験からのスタートだったので、入社時は「変数」の意味すら理解できないほどのポンコツ具合でした(笑)。
そんな私ですが配属後たくさんの先輩方に支えられ、今ではサイト内サービスのAPI開発や社内向けシステムの開発などなど、多方面の開発を任せてもらえるようになりました。 日々新しい経験を積む中で、今回は社会人2年目の夏に経験したとあるサービスの基盤リプレースプロジェクトでテーブル設計に取り組んだ時のお話をしたいと思います。
このプロジェクトが人生で初めて設計から携われたものになりますが、なんと「不動産情報サイト アットホーム」内で初めてDynamoDBを導入したプロジェクトでもあるんです…!
またデータベース(以下DB)には複数の種類があるので、アプリケーションの特性をきちんと把握してDB選択するという工程が必要になってきます。 具体的にはアプリケーションの要件からデータの更新頻度や更新パターン、パフォーマンスを定義して最適なDBを選ぶといった工夫が求められます。 そしてDBが決まったあとは、そのDBの特徴を十分に活かした設計をしていくといった手順を踏まなければなりません。
今回はDynamoDBの利用に踏み込んだ時のお話と、実際どういう風に設計していくの?という開発に入るまでのプロセスの記録を紹介したいと思います。
未経験でも活躍できた!ということを発信することで、エンジニアの世界への挑戦を応援するブログとなれたら嬉しいです。
- 今回作るのはどんなサービス??
- なぜDynamoDBを選んだのか?
- 設計①:DynamoDBのアクセスパターンを洗い出そう!
- 設計②:アクセスパターンに応じたテーブル設計をしよう!
- DynamoDBを設計してみての感想
- 最後に
今回作るのはどんなサービス??
オンラインショップで服やものを買うときのことを思い出してみてください。 「欲しいけど今すぐには買わないかな~」と思った時、皆さん一度は「お気に入り」を登録したことがあるかと思います。
「不動産情報サイト アットホーム」でも「お気に入り」を登録するという機能があり、気になる物件があればボタン一つで「お気に入り」登録することができます。
そして、「お気に入り」登録したものは「お気に入り」一覧ページで確認することができるようになっています。 そのため一度登録された物件データはデータベース(以下DB)に保存され、いつでも見られるような状態にしなければなりません。 このように単に「お気に入り」の機能といっても、実は「登録」や「一覧表示」などなど、複数の機能が含まれているのです。
そのため、「お気に入り」機能で考えられるどんなリクエストでも対応(データの提供)ができるような設計を心掛けていくことが必要です。
今回は細かく説明しませんが、これら複数の機能はAPI※を構築して画面上に提供します。構築するAPIは下図のようなサーバーレスな構造になっています。
※API...ソフトウェア同士が情報をやり取りするための窓口です。
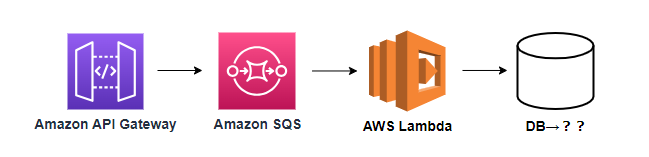
当ブログではこの「お気に入り」機能を提供するAPIを作り上げるために、APIで利用するDBのテーブル設計について考えていきましょう!
なぜDynamoDBを選んだのか?
ではまずは、今回の「お気に入り」機能にはどのようなDBサービスが適しているのかを考えていきます。
「お気に入り」機能では、ユーザー1人あたり100件近くの物件が登録できるようになっています。 それが全ユーザー分…となると、膨大なデータを管理できる環境が必要となります。 なおかつユーザーが登録後すぐに画面遷移しても登録が反映されているように、素早く処理しなければなりません。 実はこの大規模データ処理と高速化に適したDBがあります。それが「DynamoDB」です!!
DynamoDBはNoSQL(Not Only SQL)と呼ばれているDBで、AWSが提供するデータベースサービスの1つです。 DynamoDBの特徴を下表にまとめてみました。
| DynamoDB 特徴 | |
|---|---|
| データの形式 (データモデル) |
キーバリューの形式でデータを保存する (キーバリューデータベース) |
| データの柔軟性 (スキーマ) |
データの形式や属性が柔軟で、自由に変更できる |
| 拡張の柔軟性 (スケーラビリティ) |
自動的にスケーリングが行われ、データを分散して負荷を均等に分けることができる |
| 処理のスピード (パフォーマンス) |
高速な読み書きや大量のデータ処理に特化している |
今回のような大規模なデータを効率的に管理できるようにすること、また「お気に入り」機能には不動産会社や記事も「お気に入り」として登録できるようにしたいので、柔軟なデータ管理が期待できるDynamoDBを利用しようということに決まりました。
設計①:DynamoDBのアクセスパターンを洗い出そう!
次に、実際にどうやって設計していくかを考えていきましょう!
DynamoDBはRDSのように正規化を考えてテーブルを分けていくのではなく、テーブルは分けずに一つにし、その中に機能に応じて取り出しやすいアイテム(レコード)を入れていく方が効率が良いとされています。
そのため、データがどのように扱われるか(=アクセスパターン)を、設計の時点で予想できていることが大切です。
アクセスパターンは、ユースケースを定義することで見えてきます。
今の「不動産情報サイト アットホーム」の「お気に入り」機能を参考に図にしてみると、こんな感じでさまざまな使い方が見えてきますね。 実際に作成したユースケース図はもう少し複雑ですが、今回は基本的な機能をピックアップします。
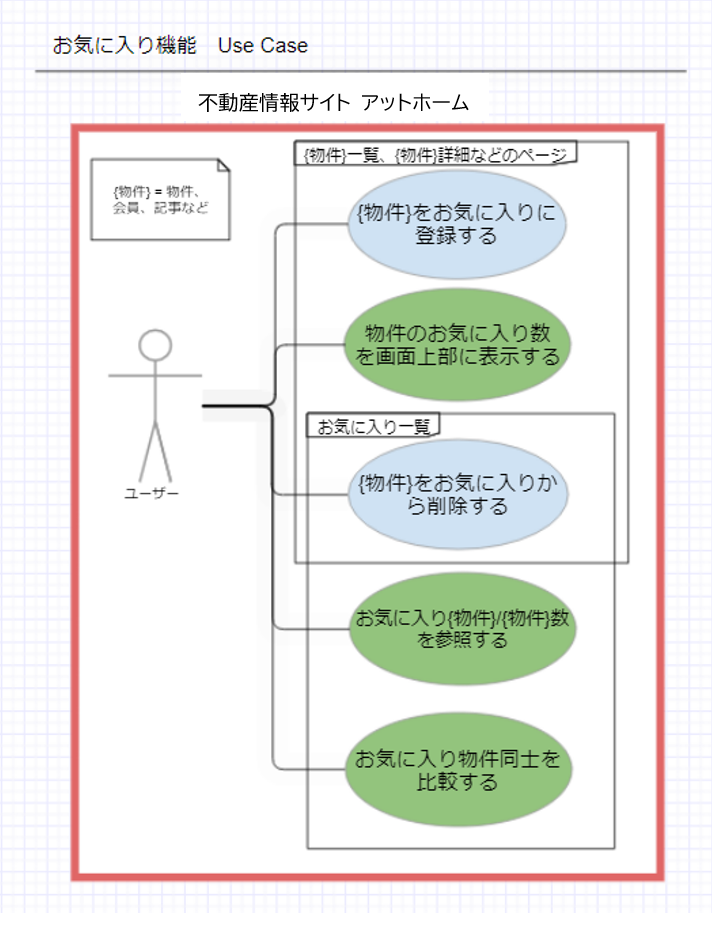
図から、以下のようなアクセスパターンを洗い出すことができました。
〇データの読み取り(抽出)
①ユーザーがお気に入りリストを参照する
〇データの書き込み(挿入/削除)
①ユーザーが{物件}に対してお気に入り登録を行う
②ユーザーが{物件}に対してお気に入り削除を行う
〇データの集計
①ユーザーがお気に入り登録した件数を集計し、画面上部に表示させる
②「お気に入り登録者数」を表示させる
設計②:アクセスパターンに応じたテーブル設計をしよう!
さて、さきほど洗い出したアクセスパターンをもとに、どのようなテーブルを作るか実際に考えていきます。
DynamoDBはデータの抽出の際、「スキャン」と「クエリ」という2つの検索方法で検索できます。
「スキャン」検索は全てのデータを読み込んだうえでデータの検索を行うので、必要のないデータまで読み込んでしまったりして 結果的に多くのリソースと運用コストがかかってしまう可能性があります。特に大量データを扱う場合は注意が必要です。
一方で「クエリ」検索は、指定された条件に基づいてデータをフィルタリングして返すので、必要のないデータを読み込むことがなく、効率的です。 そのため、できるだけ「クエリ」での抽出でまかなえるように設計をしていきます。
テーブル設計をするうえでもう一つ知っておくべき概念があります。 先ほどもちらっと紹介していますが、DynamoDBはキーバリューの形式でデータを保存するという特徴があります。
「クエリ」でデータを特定して検索するためには一意になるキー(=プライマリーキー)の指定が必要なので、プライマリーキーにする値を考えていきます。
| キー | 値の例 |
|---|---|
| パーティションキー(完全一致のみ) | ソートキー(前方一致等) |
| a#00001 | 2023-04-01T13:00:00.000#b01 |
DynamoDBではパーティションキーとソートキーの組み合わせがプライマリーキーとなります。 一意のキーを決めてから、「バリュー」にあたる属性追加していくという手順でデータを想定し、そこからテーブル設計を進めていきます。
プライマリーキーの指定では、どうしても抽出できないデータがある・・・そんな時はGSI(Global Secondary Index)やLSI(Local Secondary Index)を使います。 特にGSIを使うことで、元のテーブルのデータとは異なるキーでデータを検索することができるので、柔軟なデータ処理が実現できます。
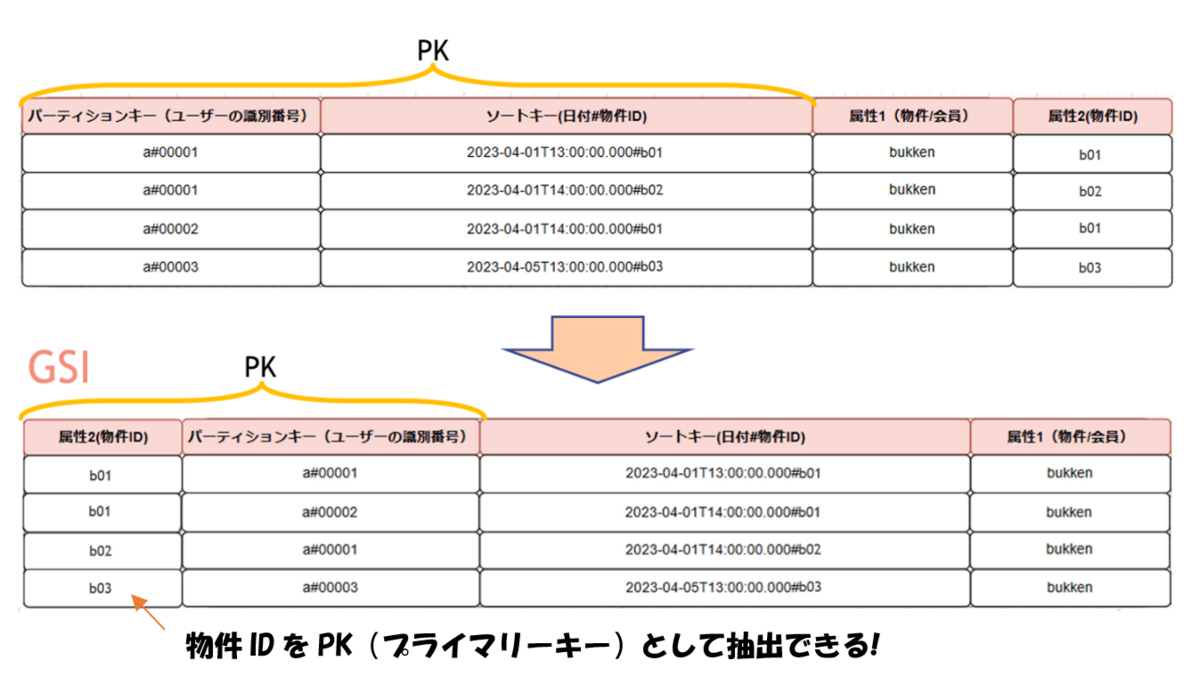
このようにして実際に見えてきた値をもとに、仮でLambdaとテーブルを作成し、期待通りにデータがAPIで抽出できるかどうか、確認していきます。 実際に設計した際は、どのユースケースでもデータが抽出できるか、抽出方法に効率の悪さはないかを確認するために何パターンか設計し、有識者にもレビューしていただきました。
このようなプロセスを経て、「お気に入り」機能のテーブルを完成することができました!
DynamoDBを設計してみての感想
今回「不動産情報サイト アットホーム」内で初めてDynamoDBを導入したこともあり、DynamoDBの特徴を1から学ぶところからはじめたので RDBMSとの考え方の違いに戸惑いながら試行錯誤を繰り返しましたが、最終的にはサービスとして十分に機能する設計ができたことはとても貴重な体験でした。
RDBMSのような固定のスキーマに縛られることなく柔軟にデータを格納できるという新しいテーブルの考え方に触れることができ、自身の成長にもつながりました。
今回の利用をきっかけに別のプロジェクトでもDynamoDBを利用する場面が増えたので、本プロジェクトで踏み切ってよかったと思います。
最後に
今回のブログを執筆した目的は、私のように未経験からでも活躍できる場が存在することを紹介することでした。
システム職は専門知識が必要であり、常に新しい技術が出てくるなど大変な部分もあるかもしれません。しかし、今回のような経験を通じて自身の視野が広がり、できることが増えていく感覚は、3年目となった今でも楽しいと感じています。
この記事を読んで、少しでもエンジニアという職に興味を持っていただけたら嬉しいです。