初めまして、デジタルイノベーショングループの橋本です。
2022年に新卒入社し、今年で2年目になります!
アットホームのお部屋探しアプリの開発保守を半年ほど担当したのち、今年の6月からデジタルイノベーショングループに配属され、現在は「不動産情報サイト アットホーム」の反響・再来訪予測モデル開発に取り組んでいます。
さて、皆さんは「予測モデル」と聞いてどういったものか想像がつくでしょうか?
AIについて知識がある方は、「機械学習」や「アルゴリズム」といったワードが思い浮かぶかもしれません。
ですが、私は最初「予測モデルってなにそれ?美味しいの?」といった感じで、知識ゼロの状態からスタートしました。
そこで今回は、そもそも機械学習の予測モデルってなに?という話から始め、そこから本題の反響・再来訪予測モデルについてご紹介しようと思います!
機械学習の予測モデルとは?
機械学習とは、AIがデータを分析する手法のひとつです。データの中からパターンや類似性を学習し、与えられたデータに対して一定の予測や判断をしてくれます。
予測モデルの種類
与えられるデータや予測の種類によって、機械学習は「教師あり学習」「教師なし学習」「強化学習」の3つに分類され、「教師あり学習」はさらに回帰モデルと分類モデルの2つに分けられます。
ちなみに、反響・再来訪予測モデルは、ユーザーが反響するかしないか、再来訪するかしないかを予測するものですので、教師あり学習の中でも、データがどちらのクラスに属するかを予測する分類モデルに当てはまります。

予測モデルの仕組み
では、予測モデルはどういった仕組みでできているのでしょうか。
まず、データとその結果あるいは正解をもとに、特徴量と目的変数から成るトレーニングデータとテストデータのセットを作成します。
そして、そのトレーニングデータをアルゴリズムにかけることで、パターンや類似性が分析され、予測モデルができあがります。
できあがった予測モデルは、テストデータを用いて性能評価をし、さらに訓練を重ねることで性能向上を図っていきます。
こうしてできあがった予測モデルに予測したいデータを入力すると、予測結果を返してくれるというわけです!
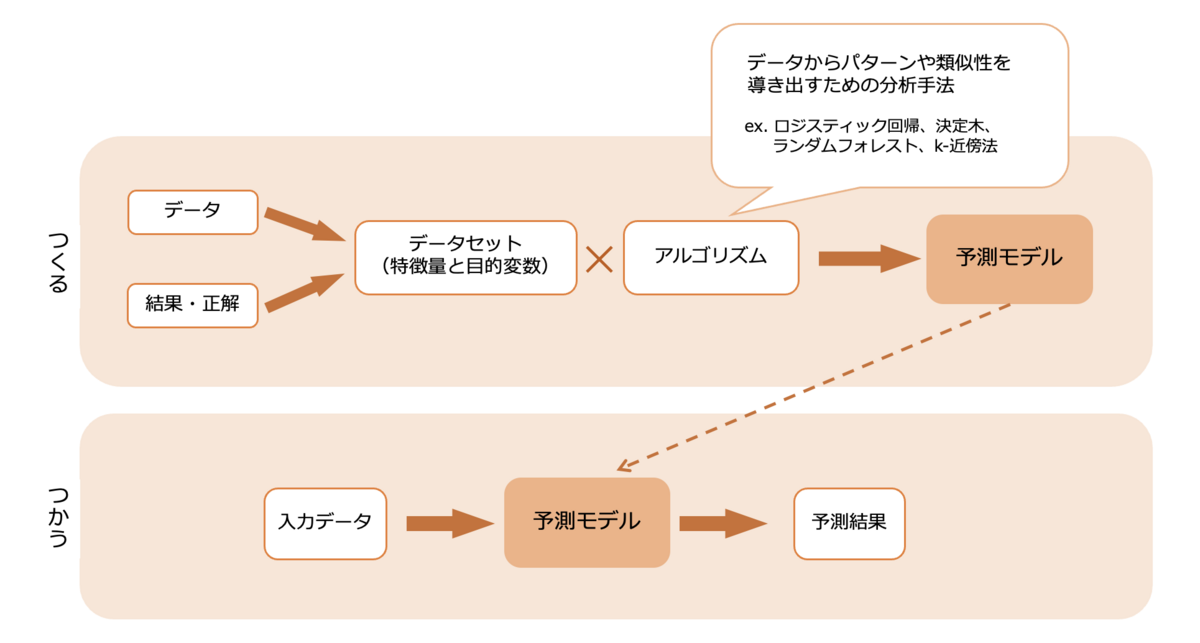
反響・再来訪予測モデルができるまで
予測モデルについてイメージしていただけたでしょうか?
ここからはいよいよ、本題の反響・再来訪予測モデルについてご紹介していきます!
予測モデルの概要
反響・再来訪予測モデルは、DataLakeに蓄積されている「不動産情報サイト アットホーム」のユーザー行動ログを教師データとして、ユーザーがサイトに再来訪するかどうかや、反響があるかどうかを予測します。
先ほどの図に当てはめると、データはユーザー行動ログ、結果は反響の有無と再来訪の有無といえます。ユーザーの来訪回数と使用端末に応じて、以下の12パターンのモデルを作成しています。

予測モデルの作成フロー
予測モデルの作成フローは冒頭にご説明したとおり、前処理したデータでデータセットを作成して、アルゴリズムにかけるという流れになっています。
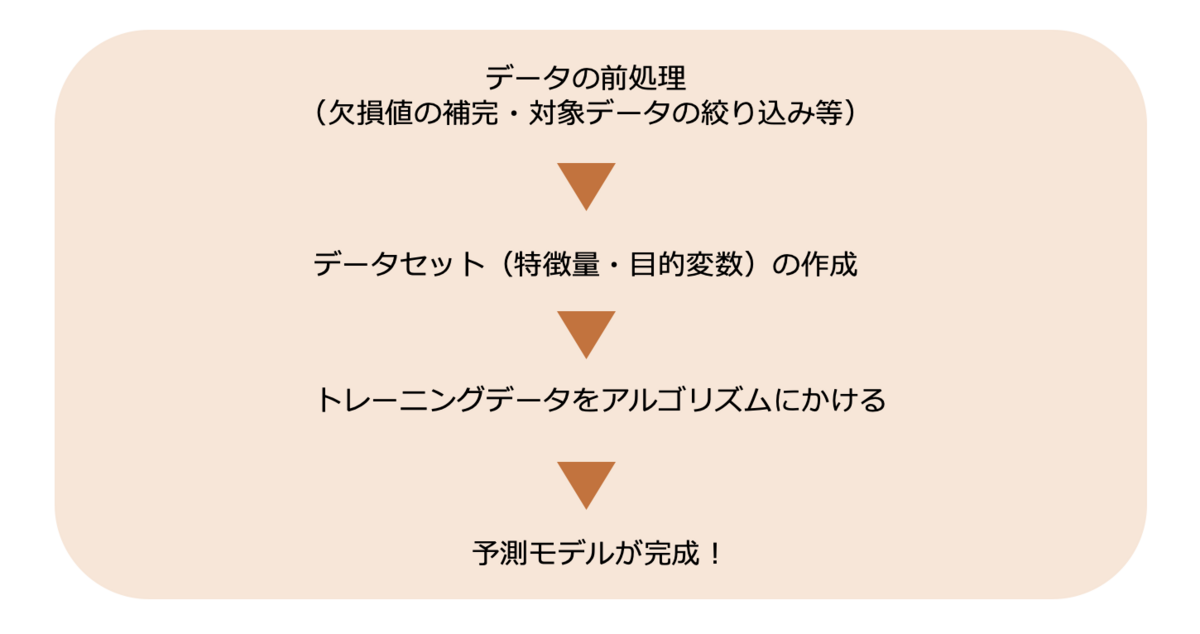
それぞれのフェーズでどのようなことを行っているのか、順番に見ていきましょう!
データを前処理する
まずは、データの前処理です。
ユーザー行動ログからユニークID、リクエスト時間、ユーザーエージェントといった項目を抽出し、不要なデータをフィルタリングします。
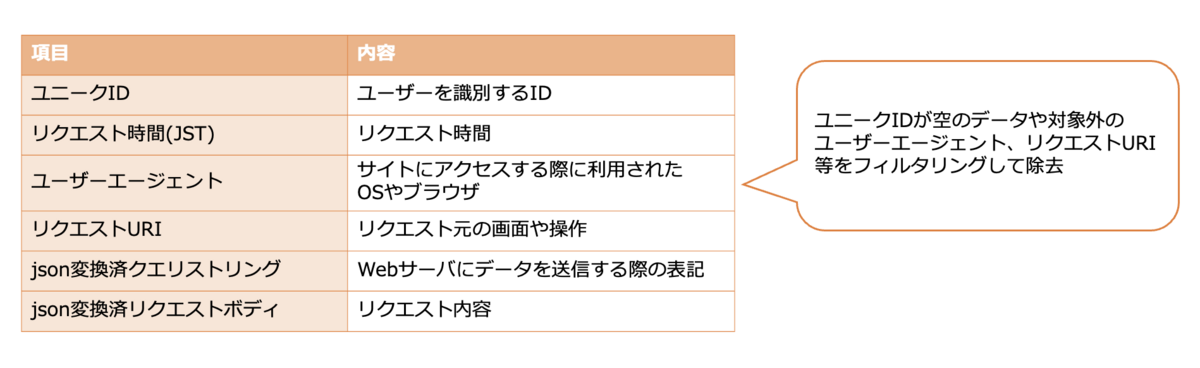
データセットを作成する
次に、前処理をしたユーザー行動ログを使用して、特徴量と目的変数を作成します。
以下の表でお見せしているのは、実際に作成している特徴量と目的変数のほんの一部です。特徴量に関しては、例えば分析する基準日から1日前の総閲覧数、2日前から7日前の間の総閲覧数といったように、抽出期間ごとに計算して項目を作成しています。

作成した特徴量と目的変数は、予測モデルの作成に使用するトレーニングデータと、予測モデルの評価に使用するテストデータに分けておきます。
トレーニングデータをアルゴリズムにかける
最後に、作成したトレーニングデータをアルゴリズムにかけます。
今回使用しているのはXGBoostと生存分析の2種類です。複数のアルゴリズムを組み合わせることで、予測結果の向上や安定化が見込めます。
XGBoost(勾配ブースティング回帰木)
複数の学習器を用いて予測の精度を上げるアンサンブル学習を代表するアルゴリズムのひとつ。
ブースティング※1と決定木※2の組み合わせで構成されている。
生存分析
イベントが発生するまでの時間の長さに対する分析手法。
今回の場合は、「ユーザー単位」や「ユーザー × 物件単位」で「Xな状態のサンプルが、Y日以内に(次の)反響が発生する割合はZ%です」という指標を分析している。Y日後までのアクセスが存在しないユーザーは、観測不可データとして取り除かれる。
※1 ブースティング:1つのアルゴリズムで学習したAI(学習器)を直列に組み合わせ、1つ前の学習器の誤りを次の学習器が修正するという操作を繰り返し行うことで、性能を向上させる手法。
※2 決定木:樹形図によってデータを分析する手法。
これで、予測モデルがひとまず完成しました!
実際に予測モデルを使用するには、まだまだ調整が必要になります・・・
反響・再来訪予測モデルの評価と活用
予測モデルの評価
こうしてできあがった予測モデルを、テストデータを用いて性能評価します。
今回は、以下の適合率と再現率という指標を使用しています。
適合率
予測モデルが陽性(反響する・再来訪する)と予測したサンプルのうち、実際に正解した(反響した・再来訪した)サンプルの割合。
適合率が高いほど、反響・再来訪すると予測したユーザーは高確率で実際に反響・再来訪する。
再現率
実際に正解したサンプルのうち、陽性と予測されていたサンプルの割合。
再現率が高いほど、 反響・再来訪するユーザーを逃さず網羅的に予測できる。
これらは、どちらかを高めるとどちらかが低下するトレードオフの関係にあるため、使用目的に合った適切なバランスになるように、再び予測モデルを訓練していくことが重要です。
予測モデルの活用
最後に、反響・再来訪予測モデルの活用についてです。
まだ小規模なデータでしか予測モデルを作成していないので、実際に活用するまでには至っていませんが、例えば、予測モデルの結果を散布図やバブルチャートなどのグラフで表すことで、ユーザーをカテゴライズしてターゲットごとに効果的な広告やサービス、レコメンドを提供することが期待できます。
反響・再来訪予測モデルの使い道は、これからさらに検討していく予定です。
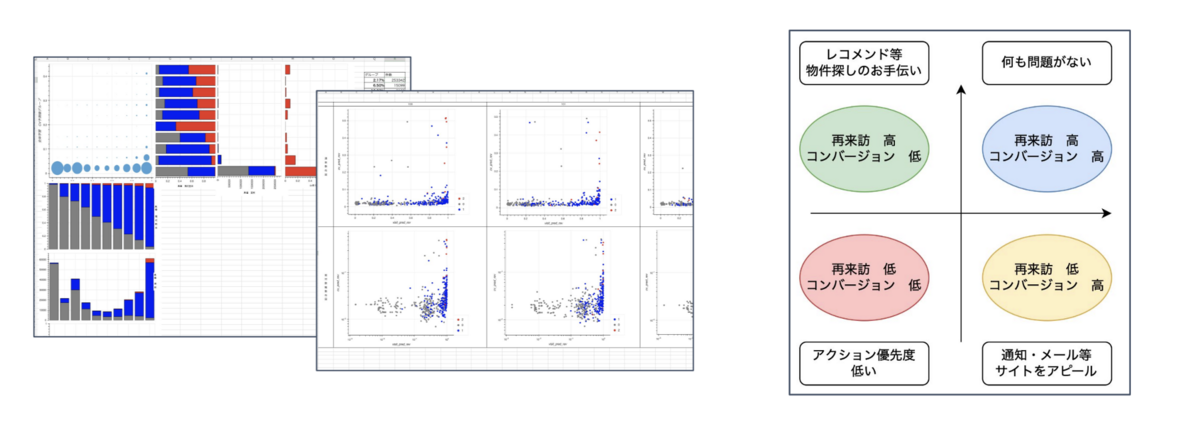
今後の開発予定
以上が、反響・再来訪予測モデルのご紹介でした!
今後は、データを大規模化したうえでモデルを再作成し、実際に使用できるように性能を向上させていく予定です。
おわりに
私は、PythonによるコーディングやAWSの知識がほとんどない状態からのスタートだったので、ここまで苦労の連続でした・・・
ですが、その分多くの知識や経験を得られたと思います。
特に、予測モデルの実装で使用したAmazon SageMakerやAWS GlueなどのAWSリソースは、アットホーム社内でもあまり使用されていなかったため、協力会社さんのお力を借りながら少しずつ理解を深めていきました。
まだまだコーディングスキルも予測モデルに対する知識も発展途上ですが、まわりの力を借りながら着実に成長していきたいと思います!
最後まで読んでいただき、ありがとうございました!